TokenAttention#
Transformer 构成了现代大型语言模型的基础。在自回归解码期间,这些模型将上下文标记的键值张量缓存到 GPU 内存中,以便于快速生成下一个标记。然而,这些缓存占用了大量的 GPU 内存。由于每个请求长度的可变性,缓存大小的不可预测性加剧了该问题,在缺乏合适的内存管理机制的情况下导致严重的内存碎片。
为了缓解这个问题,PagedAttention被提出将KV缓存存储在非连续的内存空间中。它将每个序列的 KV 缓存划分为多个块,每个块包含固定数量令牌的键和值。这种方法有效地控制了注意力计算期间最后一个块内的内存浪费。虽然PagedAttention在一定程度上缓解了内存碎片,但仍然留下了内存浪费的空间。此外,在处理多个高并发请求时,内存块的分配和释放效率较低,导致内存利用率不高。
为了解决上述挑战,我们引入了 TokenAttention,这是一种在令牌级别管理键和值缓存的注意力机制。与 PagedAttention 相比,我们的 TokenAttention 不仅可以最大限度地减少内存碎片并实现高效的内存共享,而且还可以促进高效的内存分配和释放。它允许更精确和细粒度的内存管理,从而优化内存利用率。
Features |
PagedAttention |
TokenAttention |
|---|---|---|
低内存碎片 |
✓ |
✓ |
高效内存共享 |
✓ |
✓ |
高效内存申请和释放 |
✗ |
✓ |
精细内存管理 |
✗ |
✓ |
TokenAttention的运行机制如下图所示:
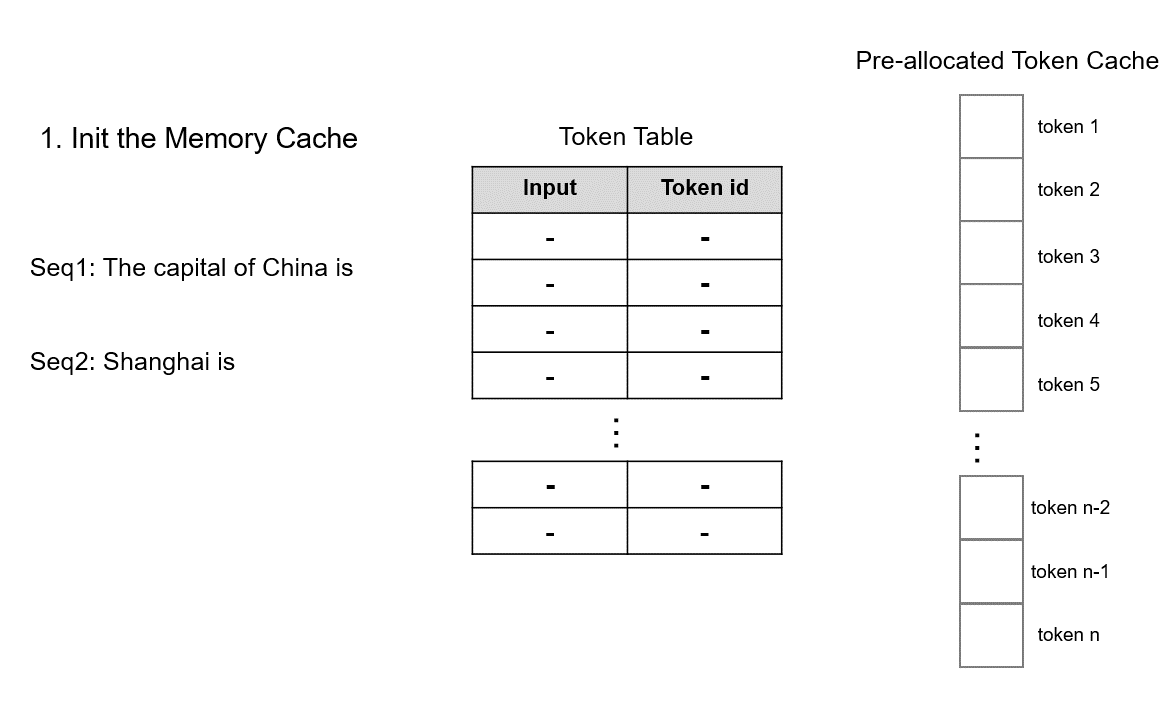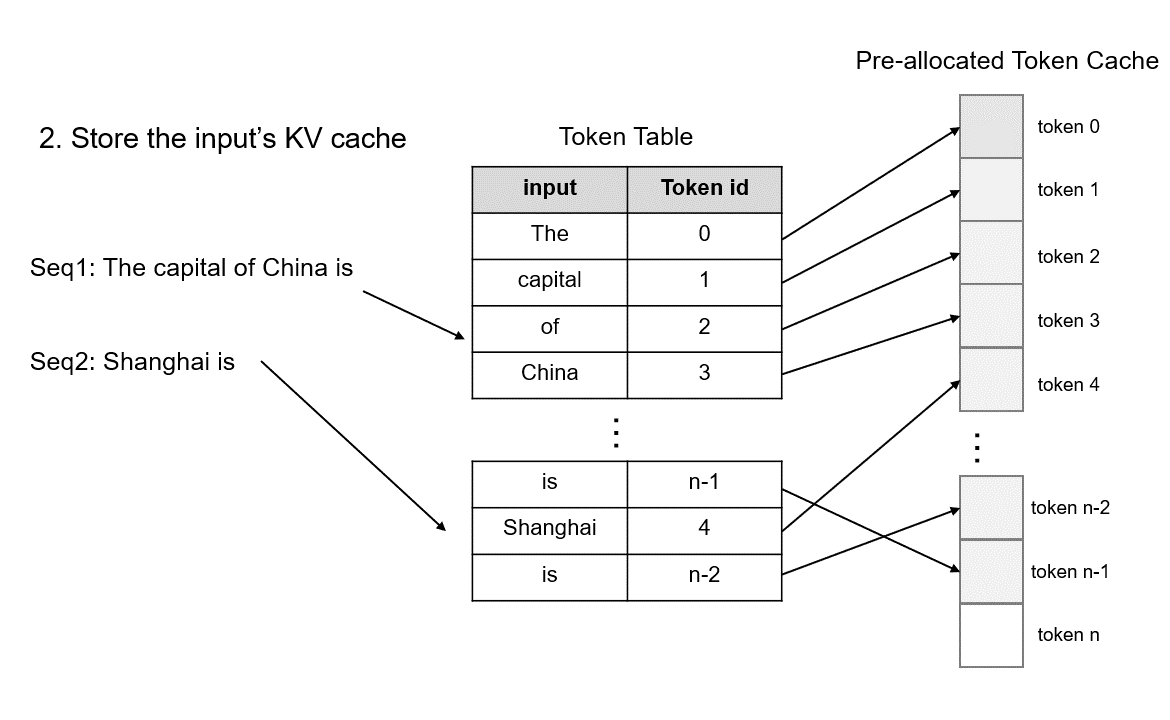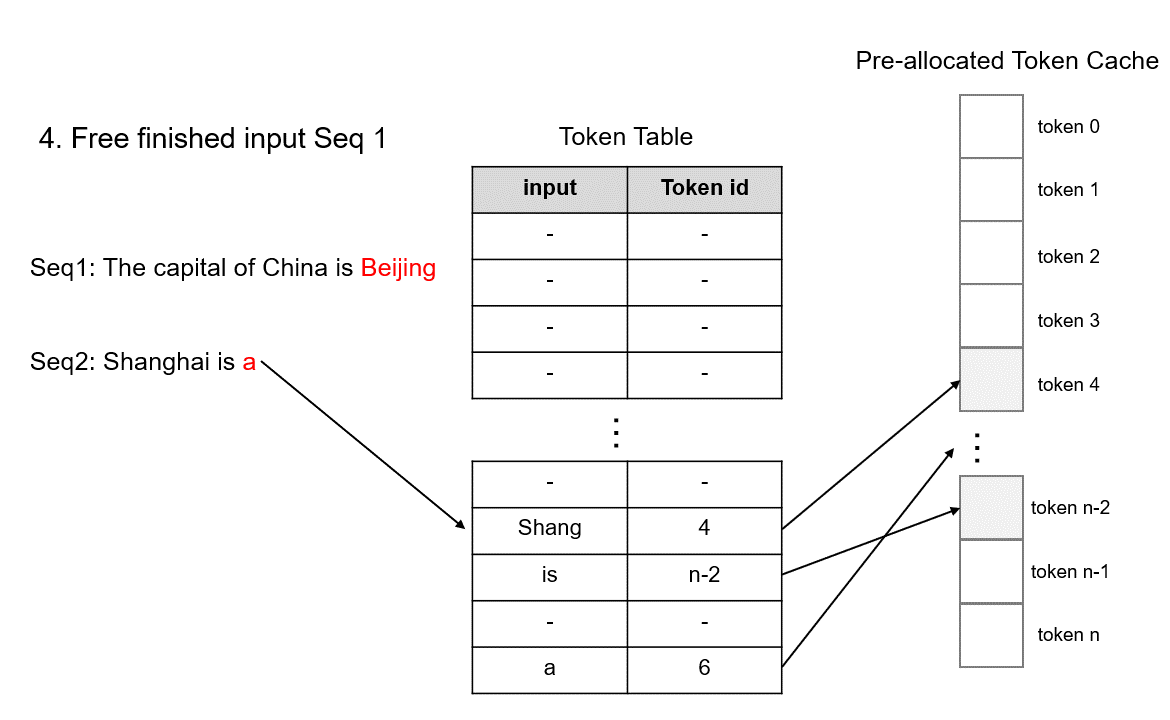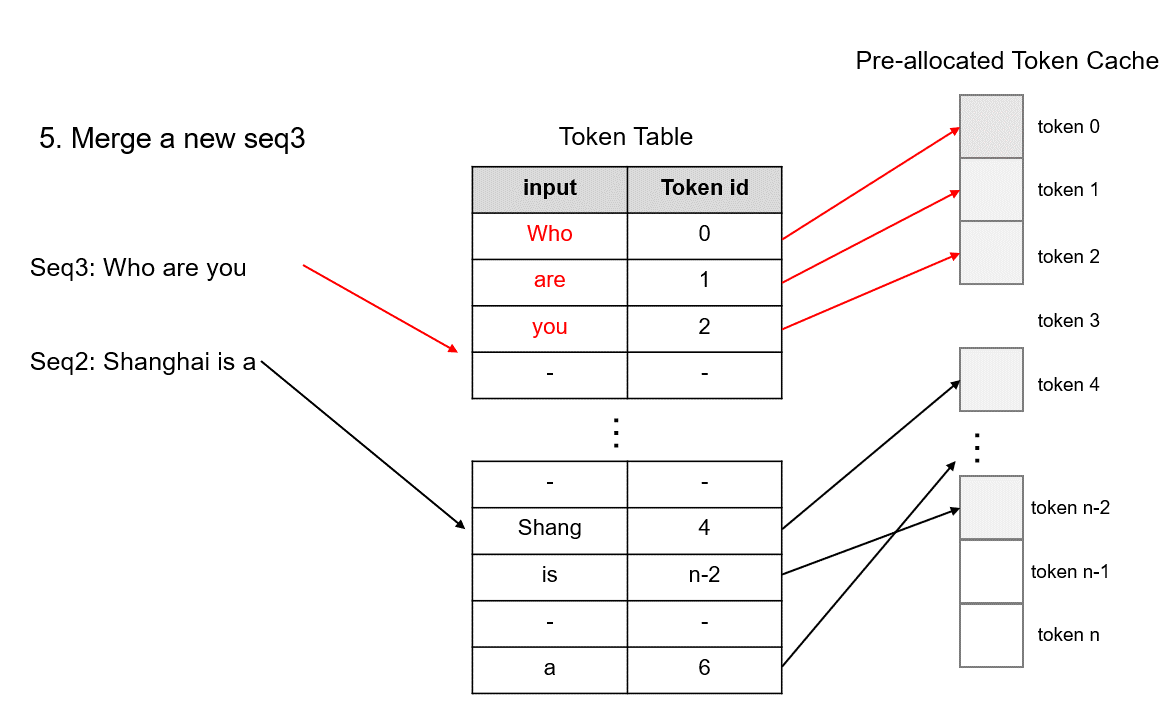
模型初始化时,根据用户设置的 max_total_token_num 预先分配 KV 缓存,并创建 Token Table 来记录输入 token 的实际存储位置。
当处理新请求时,系统首先检查预分配的Token缓存中是否有可用的连续空间用于存储键值(KV)缓存。 TokenAttention 倾向于为请求分配连续的图形内存空间,以最大限度地减少推理过程中的内存访问。仅当连续空间不足时,才会为请求分配非连续显存。由于内存管理是逐个令牌进行的,因此 TokenAttention 几乎实现了零浪费,与 vllm 相比,产生了更高的吞吐量。
我们使用 OpenAI Triton 实现了一个高效的 TokenAttention 运算符。当提供查询向量时,该算子可以根据Token Table高效地检索相应的KV缓存并进行注意力计算。
请求完成后,可以通过删除令牌表上的记录来快速释放相应的显存,从而为调度新的请求让路。由于 TokenAttention 在模型初始化时预先分配了所有 KV 缓存空间,因此可以为已完成的请求高效释放内存,并在动态调度时合并不同批次的请求,从而有效最大化 GPU 利用率。
具体步骤如下:
模型初始化时,系统根据用户设置的
max_total_token_num预先申请 KV 缓存显存,并创建 Token Table 来记录输入 token 的实际存储位置。当处理新请求时,系统首先检查预分配的Token缓存中是否有可用的连续空间用于存储KV Cache。 TokenAttention 倾向于为请求分配连续的内存,以最大限度地减少推理过程中的内存访问。仅当连续空间不足时,才会为请求分配非连续的内存。分配的空间记录在Token Table中,用于后续的注意力计算。
对于新生成的Token的缓存,只需从预先分配的Token缓存中找到未使用的空间并将相应的条目添加到Token表中即可。此外,为了有效地分配和释放Cache,我们利用Torch Tensor在GPU上的并行计算能力来管理预分配Token Cache的状态。首先,我们定义状态如下:
self.mem_state = torch.ones((size,), dtype=torch.bool, device="cuda") self._mem_cum_sum = torch.empty((size,), dtype=torch.int32, device="cuda") self.indexes = torch.arange(0, size, dtype=torch.long, device="cuda") self.can_use_mem_size = size
mem_state记录了缓存的使用状态,其中1代表未使用,0代表已使用。_mem_cum_sum用于mem_state的累积和,用于有效地识别和选择未使用的空间进行缓存分配。分配过程如下:torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self._mem_cum_sum) # select_index = torch.logical_and(self._mem_cum_sum <= need_size, self.mem_state == 1) select_index = self.indexes[select_index] self.mem_state[select_index] = 0 self.can_use_mem_size -= len(select_index)
可以观察到,我们的缓存状态管理全部在GPU上完成,充分利用了torch的并行能力,从而让系统能够高效地为每个请求分配缓存空间。
请求完成后,可以通过删除
Token Table上的记录来快速释放相应的显存,从而为调度新的请求让路。self.can_use_mem_size += free_index.shape[0] self.mem_state[free_index] = 1
由于Token级别的 GPU 内存管理,TokenAttention 可以实现 GPU 内存的零浪费。它可以准确地计算出系统可以容纳多少新Token进行计算。因此,当结合
Efficient Router来管理请求时,它可以在推理过程中不断添加新的请求,充分利用每一块GPU内存,最大化GPU利用率。